

Imagine a self-driving car navigating a familiar route every morning. It knows every turn, traffic light, and roundabout. But one foggy day, the city decides to change the traffic pattern, and suddenly the car’s decisions become erratic. What once worked flawlessly now stumbles because the environment has shifted. In the world of machine learning, this is what happens when data drifts. Models trained on one landscape begin to falter as the underlying data terrain evolves. Detecting and responding to these shifts isn’t just a technical exercise—it’s the art of staying in tune with change.
The Nature of the Drift
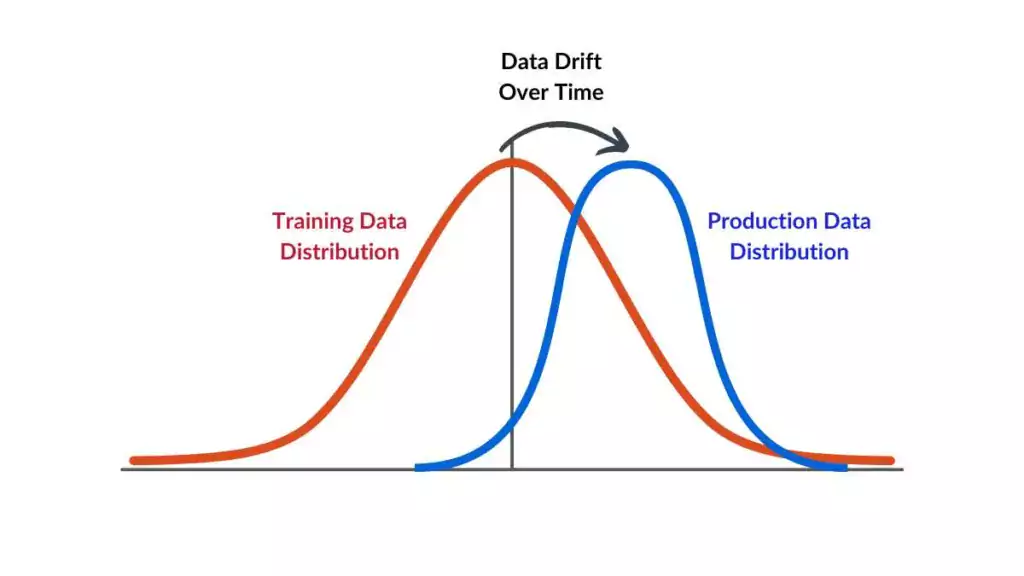
Think of data drift as the slow, almost invisible current beneath a river’s surface. The water looks calm, but over time, it reshapes the riverbank. In machine learning, input features—such as age, temperature, location, and purchase habits—start to shift in subtle ways. Maybe customer preferences change due to a new trend, or sensor readings fluctuate because of environmental factors. What’s tricky is that these changes often happen gradually, quietly eroding model accuracy until predictions lose their edge. Learners in a Data Science course in Kolkata are usually surprised to discover how much of data science is about maintenance, not just creation—keeping models alive and relevant as data flows onward.
Why Static Models Fail in a Dynamic World
Building a machine learning model without monitoring for drift is like designing a weather forecast system and never updating it for new seasons. The world doesn’t stand still; neither should your models. Consider a credit scoring model trained during a booming economy—it may misjudge risks when a downturn hits. Or an image classifier that suddenly encounters lighting conditions it was never trained on. These aren’t “bugs”; they’re natural outcomes of time’s passage. Students learning under a Data Science course in Kolkata soon grasp that a model’s success lies not in its initial performance metrics but in its long-term adaptability.
Monitoring: The Early Warning System
The first step to fighting data drift is learning to listen to your data. Monitoring acts like a continuous heartbeat monitor, tracking the health of your model’s inputs and predictions. Statistical tools—like Kolmogorov–Smirnov tests for feature distributions or Population Stability Index (PSI) for categorical variables—become your stethoscope. They detect when the rhythm of data begins to skip a beat.
Modern platforms even automate this process, creating dashboards that flag suspicious deviations. Imagine a warehouse filled with sensors—if humidity readings start creeping beyond norms, alerts are triggered long before the stock is damaged. Similarly, automated monitoring can signal when feature distributions begin shifting, giving data scientists the precious gift of time to react before performance plummets.
Building a Responsive Alert System
Monitoring without action is like a smoke detector that never sounds an alarm. Once you identify drift, the next challenge is how to respond. A well-designed alert system needs to separate noise from genuine emergencies. Not every statistical fluctuation warrants panic—some variations are seasonal or random.
One effective strategy is to tier alerts by severity:
- Yellow alerts for minor, expected deviations
- Orange alerts for noticeable shifts requiring retraining consideration
- Red alerts for critical changes threatening model validity
These alerts should integrate with communication tools like Slack, email, or dashboard notifications, ensuring teams never overlook an anomaly. Over time, data scientists learn to read these alerts like meteorologists reading storm patterns—able to tell when it’s a drizzle or when a hurricane is brewing.
Continuous Learning and Model Retraining
Detection alone doesn’t solve drift. The real solution lies in adaptation—retraining or recalibrating models with updated data. This can be manual, where analysts periodically retrain models, or automated, using pipelines that trigger retraining once drift thresholds are crossed.
A simple example: an online retailer might retrain its recommendation engine monthly to capture evolving buying habits. More advanced setups use active learning, where models constantly absorb new labelled data. The goal is to ensure the system learns in rhythm with reality, not behind it.
Automation frameworks like Airflow, MLflow, or Kubeflow help orchestrate these retraining cycles, ensuring feedback loops remain tight and transparent.
Human Intuition in the Loop
Despite automation, the human touch remains irreplaceable. Machines can spot anomalies, but humans interpret them in context. Is a spike in transactions during December a drift or just the holiday rush? Experienced data scientists draw from domain knowledge to make those distinctions. They refine thresholds, adjust alert logic, and inject interpretability into an otherwise mechanical process.
Ultimately, drift management becomes a dialogue between man and machine—data systems sensing the pulse, humans deciding the next move. This partnership embodies the true spirit of modern analytics—collaborative, adaptive, and perpetually learning.
Conclusion
Handling data drift is less about fighting chaos and more about embracing it with awareness and agility, in a world where tomorrow’s data rarely mirrors yesterday’s, monitoring and alerting systems act as the compass that keeps your models from veering off course. Through continuous observation, structured alerts, and thoughtful retraining, organisations can keep their algorithms as sharp as the day they were deployed.
For anyone stepping into this dynamic field, the lesson is clear: data science isn’t a one-time act of brilliance but a sustained commitment to listening, adapting, and evolving. The journey to mastery lies not in building perfect models, but in keeping imperfect ones gracefully responsive to a world in flux.

